Custom Elements That Work Anywhere
Safari Tech Preview 17 now has Custom Elements “enabled everywhere”, meaning it won’t be long before they’re shipping in a stable version. Since more browsers are starting to adopt Custom Elements, I thought it would be a good time to share some of the patterns I’ve learned from building and speaking about them over the past few years.
In The Case for Custom Elements I pointed out that Custom Elements should be able to work in any context where HTML works. This includes being used by popular frameworks. To that end, the patterns I’m sharing in this post will not only help you write high quality components, but should also aid in framework interoperability. Specifically I’ll be referring to React and Angular 2 in this post as those are the ones I’m most familiar with, but ideally these patterns should benefit interoperability with all frameworks/libraries.
Use properties as your source of truth
Every HTML Element has the ability to receive state through its attributes and properties. Traditionally attributes are used to set the initial state of an element but they do not update as the element changes over time. For example:
<input type=”checkbox” checked>The above line of code will render a checked checkbox. Clicking on the checkbox will uncheck it, however, the checked attribute will still exist in the DOM.

The same is true if you set a value attribute on a text input and then type in a new phrase. Calling getAttribute(‘value’) will produce the original (stale) attribute value. However, asking for the .value property will produce the correct result. In other words, attributes are useful for initial configuration, whereas properties are good for reflecting state. This leads to a few takeaways:
- The state of an element should always be determinable by its properties and it should not matter the order in which the properties are set.
- Every exposed attribute should have a corresponding property
- Updating an attribute should reflect that change to the property
- Updating a property should reflect back to an attribute only when it benefits styling, or perhaps accessibility (e.g. if you expose an API where setting a role property would reflect to an ARIA role attribute). If the property sets the corresponding attribute, and you’re using the
attributeChangedCallback, you’ll want to add a guard to prevent an infinite loop.
Here’s an example element, a Custom Menu with a selected attribute/property, that adheres to the above pattern:
class CustomMenu extends HTMLElement {
static get observedAttributes() {
return ['selected'];
}
// Called anytime the 'selected' attribute is changed
attributeChangedCallback(attrName, oldVal, newVal) {
this[attrName] = newVal;
}
// Takes a numeric index value
set selected(idx) {
if (this._selected === idx) return;
this._selected = idx;
/* Update the DOM as necessary */
}
get selected() {
return this._selected;
}
}This pattern becomes especially important when we think about interoperability with frameworks. Consider the following piece of code from Angular 2:
<custom-checkbox [checked]="item.inShoppingCart"></custom-checkbox>This is a one-way data binding which sets the checked state of the element equal to a model value, in this case the inShoppingCart property of the item object. While it looks like we’re working with an attribute here, in actuality, Angular 2 is setting a property on the element. The above line of code is functionally equivalent to:
customCheckbox.checked = item.inShoppingCart;Note: Angular 2 also provides special syntax for binding to attributes, but favors binding to properties.
One of the reasons frameworks prefer setting properties over attributes is because attributes can only pass string values, whereas many frameworks often need to pass more complex data like arrays and objects. To pass complex data with attributes would require serializing the data to JSON strings, setting those values on attributes, and then parsing that JSON on the other side to turn it back into an object. Using properties for everything avoids this extra work. This also highlights the need for a standards based way to declaratively serialize/deserialize data to/from something like attributes. Today libraries are forced to work around this limitation (either via JSX or data binding) but having an agreed upon way to declaratively pass complex data would be a big win for the platform.
Data out via events
Keep this mantra in mind: “data in via attributes and properties, data out via events”.
We’ve already covered how to get data into an element, now let’s talk about how we tell the outside world that our state has changed.
The DOM provides an easy mechanism for dispatching events in the form of the CustomEvent constructor. If you’re building a custom checkbox and a user clicks on it, the appropriate thing to do would be to tell the outside world that your checked state has changed:
class CustomCheckbox extends HTMLElement {
connectedCallback() {
this.addEventListener(‘click’, this.onClick);
}
onClick(e) {
// This should trigger a setter which updates the DOM
this.checked = !this.checked;
this.dispatchEvent(new CustomEvent(‘checked-changed’, {
detail: { checked: this.checked }, bubbles: false
}));
}
}Frameworks already have built-in mechanisms for listening to DOM events, so they should be able to work with your component if it uses this pattern. For example, to respond to this check change in React we could do the following:
class SignUp extends React.Component {
componentDidMount() {
this.refs['signup'].addEventListener(
'check-changed', this.onCheckChanged.bind(this)
);
}
onCheckChanged(e) {
/* Notify the outside world via callback or Redux */
}
render() {
return (
<div>
<span>Join Our Newsletter!</span>
<custom-checkbox
ref="signup"
checked={this.props.user.hasJoined}>
</custom-checkbox>
</div>
);
}
}Note: There’s an ongoing discussion about improving event handler interop between Web Components and React over on GitHub. Till that issue is resolved you can use a library like webcomponents/react-integration to smooth over interop issues.
Or in Angular 2:
<span>Join Our Newsletter</span>
<custom-checkbox
[checked]="user.hasJoined"
(check-changed)=”user.hasJoined=$event.detail.checked”>
</custom-checkbox>The key thing is that we’re telling the outside world that our state has changed. For top-down, unidirectional data flow systems this is important because it affords them the opportunity to revert that change if it doesn’t match their model. For example, React listens for the change event from the native <input type=”checkbox”> element, and if it doesn’t match React’s internal model, it reverts the change. Making sure our Custom elements dovetail into this system means they’ll ultimately be more shareable across the entire ecosystem.
When I showed this pattern off recently someone asked if it would be better to dispatch the events inside of the property setters, for example:
set checked(val) {
this._checked = val;
/* do any other updates we need */
this.dispatchEvent(new CustomEvent(‘check-changed’, {
detail: checked: val
}));
}The danger with doing this is you may end up creating an infinite loop if there’s an external listener for the event which in turn updates the property. Looking again to native elements, it seems that their event dispatching only takes place when some external force is acting upon the element, e.g. someone clicked, someone typed, something loaded, etc. Hence, we don’t dispatch check-changed when the public property is set, but instead only when someone clicks on the checkbox.
Also note that special care should be taken when working with events to prevent leaking too much information to the outside world. In general, don’t bubble events unless they are semantically meaningful. For example, changed is not a very semantically meaningful event, whereas document-opened would be. Non-semantic events can leak up and another element may accidentally handle them. Plus it makes things less explicit. Colocating the event dispatcher, and the element handling it makes relationships easier to grok. By default, custom events won’t bubble out of shadow roots without the composed: true flag set, so Custom Elements using Shadow DOM are default encapsulated w/ custom events.
In cases where you do need to bubble events, the element that handles the event should probably call event.stopPropagation(). Unless that element also has a good reason for letting the event continue to bubble up.
Favor a declarative API over an imperative API
It is preferable to always use properties (or attributes that reflect their changes to properties) to define the state for your component. This means avoiding methods which mutate state without reflecting those changes to the corresponding properties and dispatching the appropriate events. By focusing on properties you make it much easier to build your app in a declarative fashion.
<custom-dialog opened>
<!-- which is the same as saying... -->
customDialog.opened = true;Instead of:
customDialog.open();In the example above, the state of the app can be reasoned about entirely using HTML, whereas the second example requires imperative setup code in JavaScript (specifically calling a method). The declarative version lends itself well to systems like React/Redux and Angular 2 which favor a top-down data flow model, as they can just pass in the appropriate attributes/properties to make the state in the DOM match the state in their data stores.
Avoid sync issues with Shadow DOM
Frameworks and libraries which manage the DOM often have systems to dictate when components can render and how the DOM is updated. A good example is React’s virtual DOM diffing which creates a kind of snapshot of the DOM and uses it to reconcile changes whenever components update their state.
Custom Elements, on the other hand, render DOM in response to lifecycle callbacks triggered by the HTML parser. This means they may operate outside of a library’s ability to snapshot the DOM. This has the potential to lead to sync issues as the Custom Element upgrades and renders its own DOM that then does not match the snapshot the library is diffing against.
Shadow DOM offers a way to protect both the Custom Element and the library from getting their wires crossed. It does this by creating a shadow root, essentially a self-contained tree which the Custom Element can treat as its own private world, obscuring its internal DOM state from the rest of the page. Many of the native elements that you work with every day (input, video, etc) use Shadow DOM to encapsulate their internals.
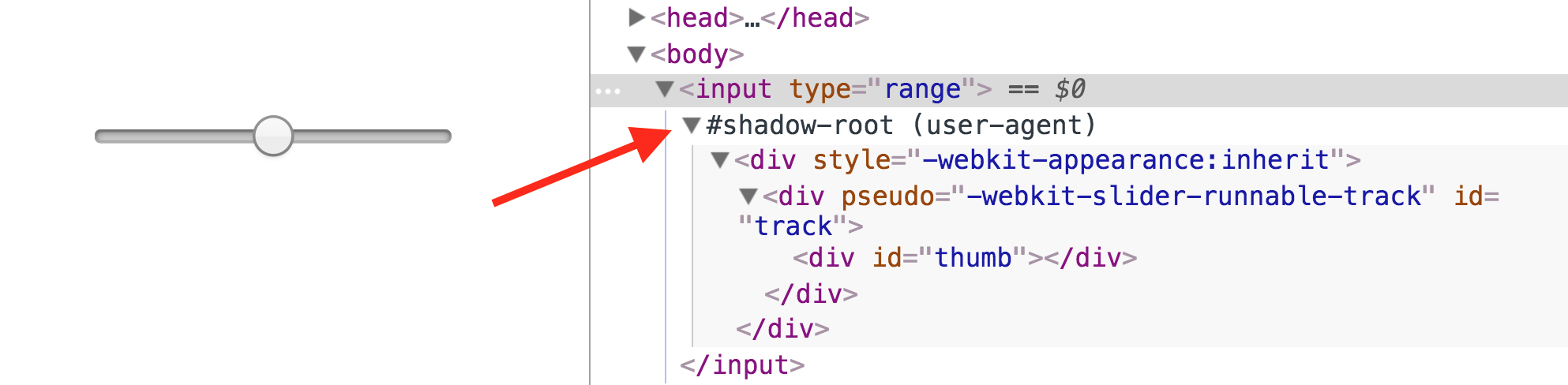
To see this go to the Settings in Chrome Dev Tools and check “Show user agent Shadow DOM”.
Adding Shadow DOM to a Custom Element is quite easy:
class XFoo extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
this.shadowRoot.innerHTML = `<p>Hello from x-foo</p>`;
}
}
window.customElements.define('x-foo', XFoo);Or if you prefer using a <template> element for your markup:
<template id=”x-foo-tmpl”>
<p>Hello from x-foo</p>
</template>class XFoo extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
const tmpl = document.querySelector('#x-foo-tmpl');
this.shadowRoot.appendChild(tmpl.content.cloneNode(true));
}
}
window.customElements.define('x-foo', XFoo);Using Shadow DOM will ensure that your element avoids potential conflicts with any framework managing the page and, as an added bonus, you’ll get style scoping for free!
Wrapping Up
The patterns listed above are based on conversations I’ve had with framework authors and I imagine over time we’ll need to augment and add to this list. Because the Web Component ecosystem is still fairly new, it feels like a good time to explore these patterns before possible bad habits get burned in and become widespread. If you’re building a Custom Element, consider giving these patterns a shot, and be sure to share your final project over on the new Web Components catalog. Also leave some comments! Thanks :)
Big thanks to Addy Osmani, Justin Fagnani-Bell, Jeff Cross, Rob Wormald, Sebastian Markbåge, and Trey Shugart for their reviews.